An Overview of OGM
OGM begins with the isolation of ultra-high molecular weight (UHMW) DNA from blood, bone marrow aspirates, cultured cells (including chorionic villi and amniocytes), tissue, or tumor biopsies. A single enzymatic reaction places fluorescent labels all throughout the genome at a specific sequence motif. The labeled DNA molecules are linearized in nanochannel arrays on the chip. Changes in the patterning or spacing of the labels are identified by software solutions to accurately detect all classes of structural variants (SVs). The OGM data generated can be analyzed alone, or in combination with sequencing or array data.


OGM begins with the isolation of UHMW DNA from a variety of fresh or frozen sample types. Unlike standard DNA isolation methods such as precipitation, column, or bead-based methods, which yield molecules too small and fragmented for assembly, the Bionano sample prep method produces large molecules (>150 kbp) needed to span large and complex SVs.
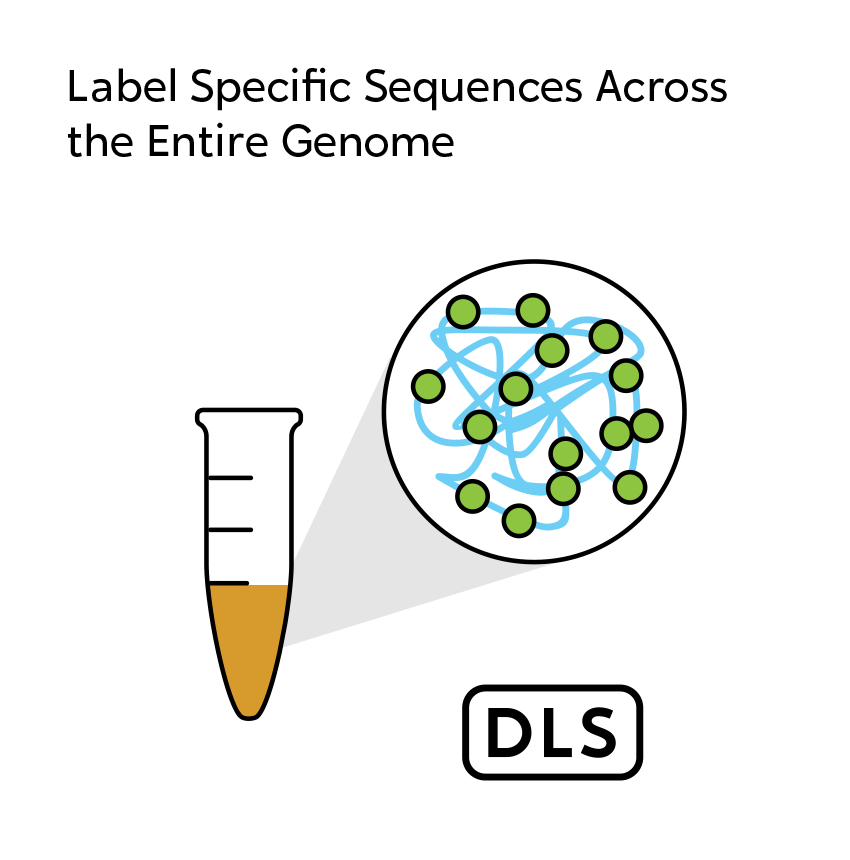
In a single enzymatic reaction, the Bionano Direct Label and Stain (DLS) workflow recognizes a 6 bp sequence motif occurring approximately 14-17 times per 100 kbp in the human genome and transfers a fluorescent label to it via covalent modification. This labeling step results in a uniquely identifiable sequence-specific pattern of labels to be used for genome map assembly.
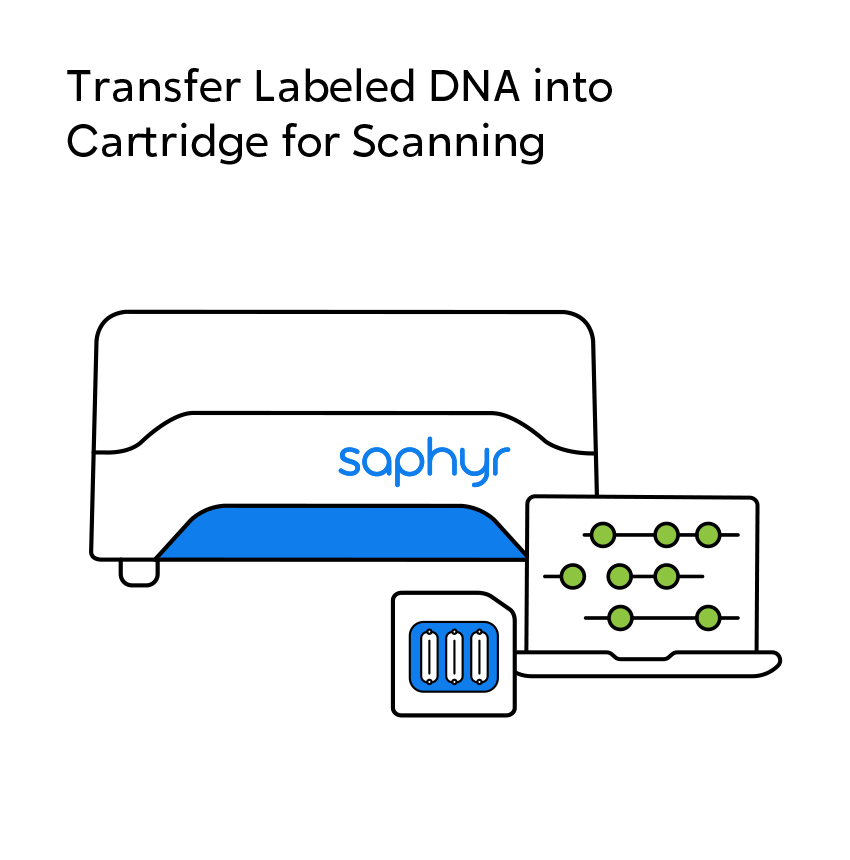
The labeled DNA is loaded into the inlet and outlet sides of a single flow cell of a chip, allowing electrophoresis of molecules from inlet to outlet.
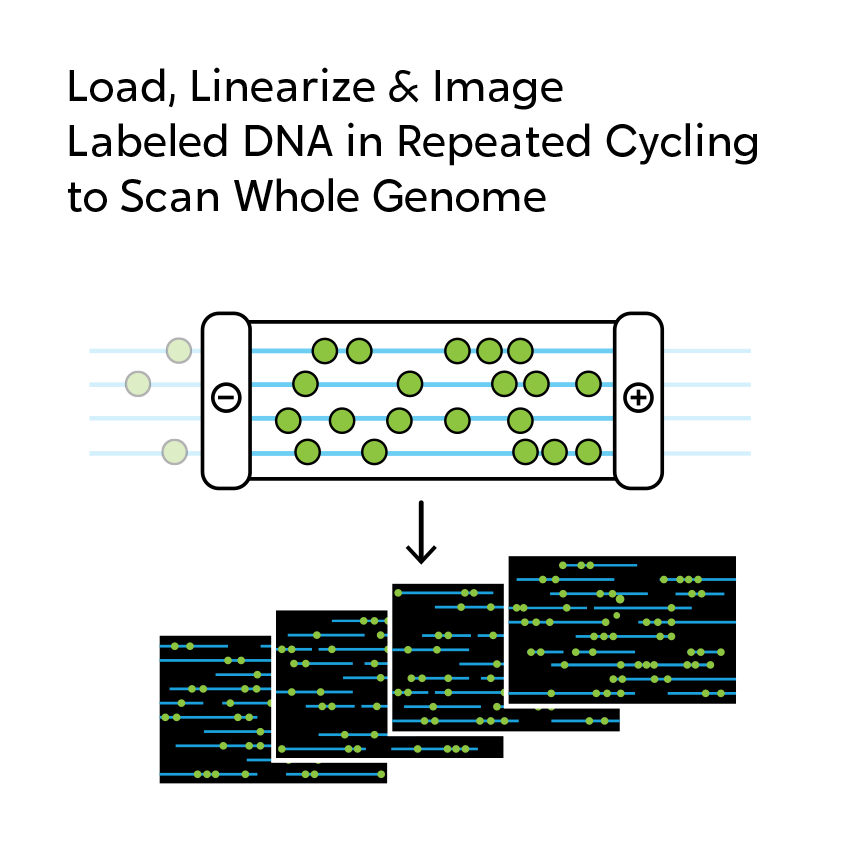
The genome mapping instrument controls the movement of DNA in the flow cell by electrophoresis. A gradient of micro- and nanostructures, upstream of the nanochannels, gently unwinds and guides DNA into the nanochannels. The nanochannels allow only a single linearized DNA molecule to travel through while preventing the molecule from tangling or folding back on itself.
Once the DNA is stretched inside the nanochannels, the high-resolution camera images them. This environment allows molecules to move swiftly through hundreds of thousands of parallel nanochannels simultaneously. Long molecules spanning beyond a field of view are stitched together. Once imaged, the molecules are flushed, and the process is repeated with new molecules.
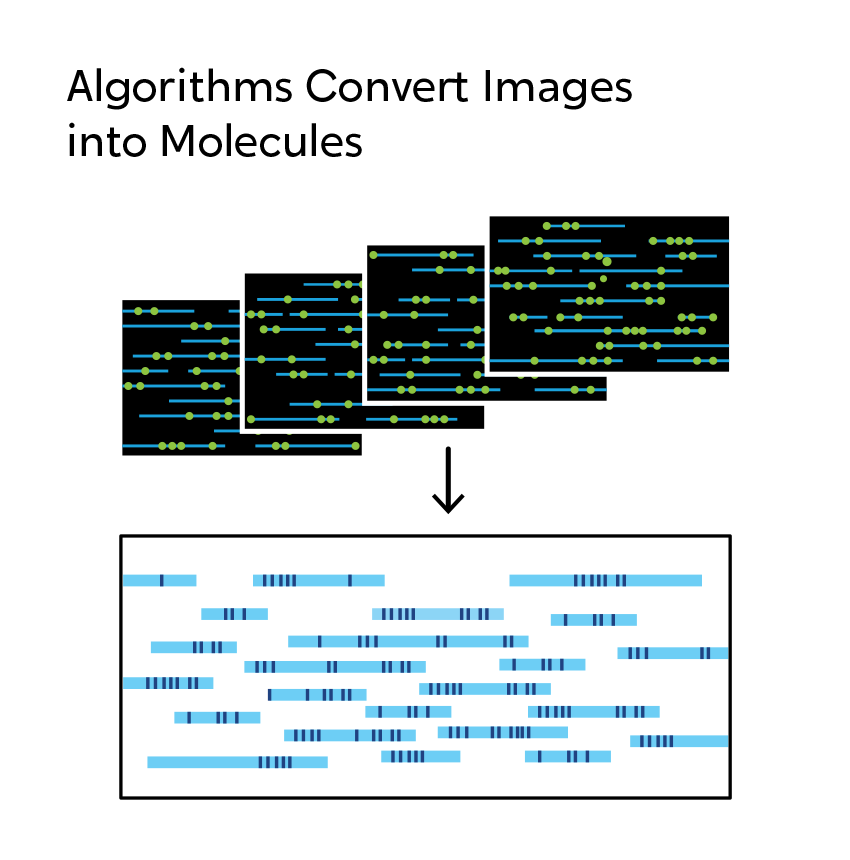
Once raw image data of labeled long DNA molecules is captured by the genome mapping instrument, it is converted into digital representations of the motif-specific label pattern.
Observe SVs Directly with OGM
When using OGM, structural variations are observed, not inferred as they are with next-generation sequencing (NGS). When short-read NGS sequences are aligned to reference genomes, megabase-size native DNA molecules are imaged, and most large structural variations or their breakpoints can be observed directly in the label pattern on the molecules. In addition, SVs can occur in the repetitive sequences that make up two-thirds of the genome. NGS has significant, known limitations with assessing variation in and around repetitive sequences. OGM is free from these constraints, making it possible to reveal those changes that can contribute to human disease.

Related Applications



Learn More about OGM



Learn from a specialist: Request a live overview of how OGM works and discuss how your research can benefit. Request an OGM overview
Request an OGM Overview
